Sexism in gaming isn’t a new thing at all — good ol’ Dungeons & Dragons was full of it. Here’s Gary Gygax, one of the creators of the game, opining on women in gaming sometime in the early 2000s:
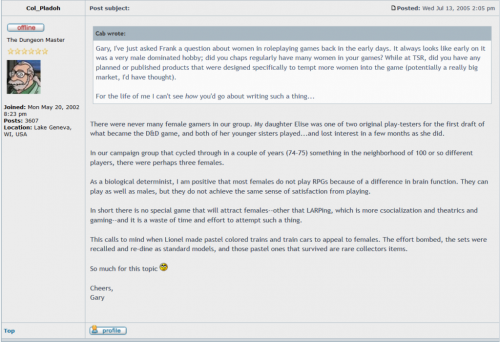
There were never many female gamers in our group. My daughter Elise was one of two original play-testers for the first draft of Wi, Usa ‘what became the D&D game, and both of her younger sisters played…and lost interest in a few months as she did.
In our campaign group that cycled through in a couple of years (74-75) something in the neighborhood of 100 or so different players, there were perhaps three females.
As a biological determinist, | am positive that most females do not play RPGs because of a difference in brain function. They can play as well as males, but they do not achieve the same sense of satisfaction from playing.
In short there is no special game that will attract females–other that LARPing, which is more csocialization and theatrics and gaming–and it is a waste of time and effort to attempt such a thing.
This calls to mind when Lionel made pastel colored trains and train cars to appeal to females. The effort bombed, the sets were recalled and re-dine as standard models, and those pastel ones that survived are rare collectors items.
So much for this topic.
One thing that jumped out at me was his flat statement that he was a “biological determinist”. Gygax had no training in biology, no college degree at all — he was an insurance agent before he became famous as a gamer. You can dismiss anything he says about “brain function” as a product of ignorance.
He mentions that few women were interested in his game in 1974-75, when they “tested” the idea. Women were not interested, according to him, because their brains were different. I have an alternative explanation: here’s Gygax writing about the subject in 1975.

I have been accused of being a nasty, old, sexist-male Chauvinist-pig, for the wording in D&D isn’t what it should be. There should be more emphasis on the female role, more non-gender names, and so forth. I thought perhaps these folks were right and considered adding women in the ‘Raping and Pillaging_ section, in the ‘Whorses and Tavern Wenches’ chapter, the special magical part of dealith with ‘Hags and Crones’, and thought of perhaps adding and appendix of ‘Midieval Harems, Slave Girls and Going Viking’. Damn right I am a sexist. It doesn’t matter to me if women get paid as much as men, get jobs traditionally male, and shower in the men’s locker room. They can jolly well stay away from war-gaming in droves for all I care. I’ve seen many a good wargame and wargamer spoiled thanks to the fair sex. I’ll detail that if anyone wishes.
Wow. Just wow. What an asshole.
Were you shocked by gamergate in the 2010s? I was. I shouldn’t have been, if I’d been paying attention in the 1970s. I don’t think Gygax was a cause, but a symptom of an attitude common at the time.
Let’s not forget the weird racism in old school D&D, either. I suspect he was a “race realist” in addition to being a “sex realist”, and now it’s coloring my impressions of the game.









